Applying Textures to Untextured Images Using Neural Networks
Abstract
Producing textures for images is a labor intensive process that can take significant human time. Additionally, older source material, such as video games from antiquated hardware, lacks textural detail of the level modern systems contain. Finding a fast and effective way to automatically apply textures to untextured images could significantly reduce labor for projects that require handmade textures and additionally efficiently revitalize older source material. We attempt to apply textures automatically to non-textured images of 3d renderings using convolutional neural networks as a final step in a graphics pipeline. Our final product is a system in which you can pass an untextured rendering with a texture cue into a trained convolutional neural network that then outputs a fully textured result.
Technical Approach
Our original proposal was to arbitrarily texturize geometric objects inside a scene. The holy grail was to select certain objects in a scene, specify a texture, then ask a neural network to accurately texturize that object. However, after talking with Pratul, he suggested that we start with an easier problem - learning how to texturize a single plane in 3D as a basis for solving this problem. If this was successful, then we could build up for the hard problem of texturizing more complex geometries.
We approached the problem with the CNN derived in Chen and Xu et. al. 1. This CNN shows that a simple architecture (fully-convolutional) with a simple loss function (L2 loss) could learn a to approximate a large number of operators such as L0 smoothing and style transfer efficiently. We figured that our problem was similar, except that we wanted to encode information about the desired texture using some sort of cue passed to the network.
Rotating Plane
Our first approach was to try and pass in the texture directly to the network. This would validate whether the network could learn to “wrap” the texture around the geometry. If it could easily learn the homographic transformation of a flat plane to the rotated plane, then we could use this method combined with information about the geometry to automatically apply the texture. Unfortunately the problem of learning geometric transformations with neural nets is quite difficult. The central issue in this task arises in the size of the perceptive field of each neuron. Consider a simple translation. If a pixel is to be translated pixels from it’s input position to it’s output position. This thus implies that the perceptive field of the final pixel must contain pixels at least pixels away. More generally, any translation mapping a pixel in the input to a pixel pixels away requires the perceptive field of the final pixel to be at least . Perceptive field increases with depth of the neural network. Often, the perceptive field of hidden units does not become large enough to even possibly learn such transformation until very deep layers, reducing the net’s ability to learn robust homomorphic mappings. Attempts to embed the structure of geometric transformation, such as transformation matrices, in which the parameters of these structures are learned have demonstrated success. cite As our initial model did not contain any such elements, the model was unable to learn the desired transformations. While it is difficult to accurately deduce what is being learned by any network, the fact that the net couldn’t even match the edges of the output suggests this perceptive field may have been present, as such an observation is indeed consistent with this pattern.
Rotating Plane with Texture Cue
We switched gears, and instead tried to preserve the geometry but provide a sort of texture cue. This would be the first building block towards making an interface where a user could draw on the texture using a paintbrush, and then have the network infer that the texture should extrapolate to the rest of the object. Our first test was to insert a circular cue at the center of the image.
 From the picture above, you can see that the net from 1 seemed to learn that the color of the cue should be extrapolated to the rest of the plane, but failed to infer anything about the texture. We suspect that the L2 loss enforced too strong of a constraint on any single example, and with gradient descent ended up learning to average all the textures together, resulting in a smooth surface.
From the picture above, you can see that the net from 1 seemed to learn that the color of the cue should be extrapolated to the rest of the plane, but failed to infer anything about the texture. We suspect that the L2 loss enforced too strong of a constraint on any single example, and with gradient descent ended up learning to average all the textures together, resulting in a smooth surface.
Pre-training attempt with real images
We also thought we could possibly pre-train a network to approximate textures for people by first “wiping away” the textures and then applying them afterwards. We took the MIT-Adobe FiveK dataset 3, wiped away the textures using $L_0$ gradient minimization 4. However, when we first tried to train the network on this task, our results were not satisfactory, so we decided to put the idea on hold.

Style Transfer
We went back to the drawing board and realized that our problem was not that much different than artistic style transfer, originally proposed by Gatys et al. 8. The basic idea is that we can use a CNN trained on ImageNet to extract feature representations of an image’s “style” which is very analogous to the texture of an image. This feature representation can then be transferred to any image using convex optimization by encoding the style featurization as an element of a loss function. The specific style loss term is
where and , are the grammian self-similarity matrix of layer activations (for the style image) and (the content image) respectively. The entire loss function used in style transfer becomes.
We applied this optimization technique, and we got the result below
![]() The image on the left is the result of applying the technique where the rotated plane is the source content and the original texture is the style, and the result gets somewhat close to the ground truth on the right. It may seem like we solved the problem here, however this method is rather slow (takes about 2 minutes per image) and doesn’t provide the “drawing” flexibility we desired.
The image on the left is the result of applying the technique where the rotated plane is the source content and the original texture is the style, and the result gets somewhat close to the ground truth on the right. It may seem like we solved the problem here, however this method is rather slow (takes about 2 minutes per image) and doesn’t provide the “drawing” flexibility we desired.
Style Loss
The style transfer approach did seem to promise that using a style loss as part of our neural network objective would be promising. Specifically we sought to replicate the optimization objective used in Fast Style Transfer (Johnson et al. 6) which uses a style loss during the network training procedure.
Our new loss function became
where denotes the network. After experimenting with the style constant we eventually got the results below
 You could argue that the network did a better job of understanding that the texture must be replicated, however it didn’t seem to learn anything meaningful with that result. Again, it’s likely that the loss function did a terrible job of actually directing the results to something favorable.
You could argue that the network did a better job of understanding that the texture must be replicated, however it didn’t seem to learn anything meaningful with that result. Again, it’s likely that the loss function did a terrible job of actually directing the results to something favorable.
Pix2Pix
We postulate that these loss functions functions failed to provide the neural net with useful feedback due to the fact that they enforced a high degree of similarity to individual instances of the target outputs when the input to the model did not provide enough information to accurately reproduce the target output. This task as we have currently formulated it is more akin to a generative task, in which the neural net is asked to output a plane with a texture conditioned on the input plane’s geometry and texture cue. In this vein, we decided to switch to a cGAN (Conditional Generative Adversarial Network). cGAN’s are an extension of GAN’s. In a GAN, network called a generator attempts to produce output seeded by random noise similar to a target class. A second network called the discriminator is exposed to real instances of the target class and generated instances made by the generator. The discriminator attempts to properly classify these instances as real or generated instances. The generator attempts to produce output that the discriminator classify incorrectly as true instances.
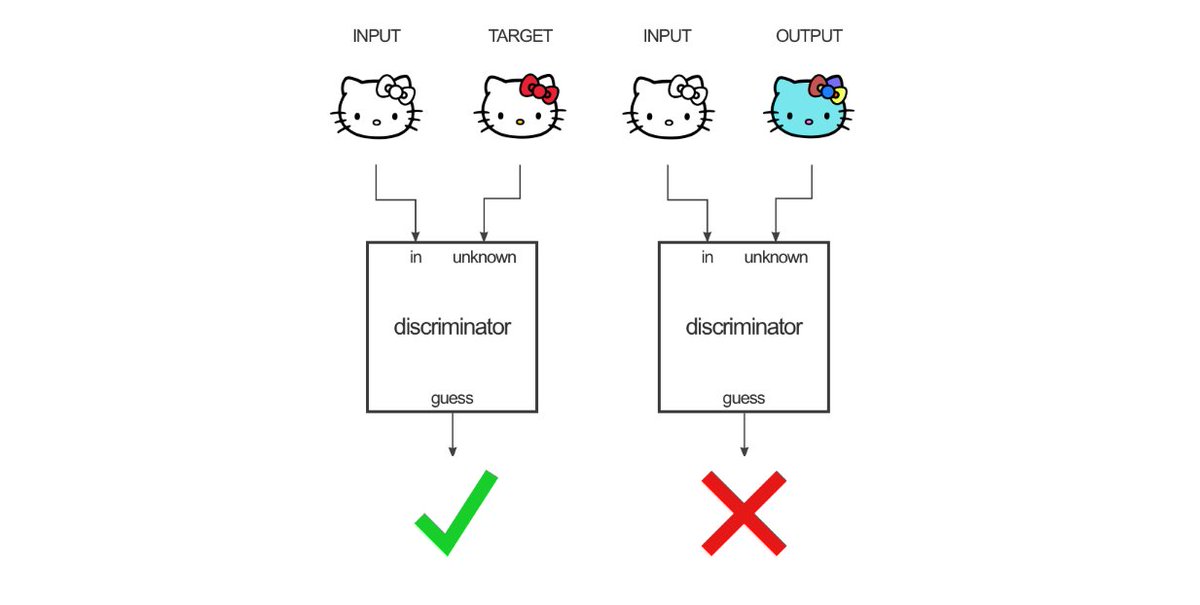
This results in a loss formulation where the discriminator attempts to minimize the loss of a classification problem, usually cross-entropy loss, where the classes are real and generated instances. The generator thus attempts to maximize this function. The gradients from these two loss functions are used to train the networks in tandem. As training progresses, the discriminator more accurately can classify true class instances and out of class instances, including generated images. The generator more accurately produces output that the discriminator misclassifies, thus producing output closer to the true class. Equivalently, one could characterize the discriminator as learning a loss function the generator is attempting to minimize. A cGAN is a variant of GAN in which the output of the generator is conditioned on some output in addition to being seeded with random noise. cGAN’s have been conditioned on text, embeddings, and images. We proceeded by framing our problem as conditionally generative task, using Pix2Pix 7, a cGAN architecture for producing output images conditioned on an input image, we replaced our previous network with Pix2Pix.
Multiple Rotations and Texture cues
In an attempt to more robustly learn general rotation and textures, we trained Pix2Pix by producing a dataset of planes randomly rotated in space, with the red channel representing depth via intensity that varies with depth. We additionally apply a random mask to the planes over which we apply a cue of our goal texture. We then provide rotated planes with the same texture applied as ground truth images. In this framework, we are conditioning the output of our generator on the geometry of the plane and the texture cue we apply to the plane, both parameterized by the input image. We then attempt to make the output of the model resemble planes rotated to the same orientation with the same texture. See below for an examples of triples of input, output, and ground truth images
Before adding this modification, our network did not generalize well to random texture cues, as you can see in the following images:



Results
For the texture cue approach, the pix2pix method was able to extrapolate the texture from our cues. By training on a dataset of texture cues that we hand drew ourselves, we further improved the generalization capabilities of our network.



We then created a web app that allows users to draw on their own texture cues and see how the network performs. You can see a demo of that in our video.
As a side result, we also ran the Pix2Pix network trained on the L0 dataset mentioned earlier. The network ended up texturizing nature scenes very accurately as you can see below.



However, the method failed on nearly all image with faces, likely because the $L_0$ method wiped away the important edge details that would otherwise denote the geometry of the image.

Future Directions
With this, we’d like to continue to build towards the goal of generalizing towards images with a variety of geometries and images with multiple geometries as well. We believe that the results are also promising - we think that there’s an opportunity to use this texture cue concept to inform this sort of problem and possibly build up to texturizing new pieces of real images.
References:
[1] Chen, Qifeng, Jia Xu, and Vladlen Koltun. “Fast image processing with fully-convolutional networks.” IEEE International Conference on Computer Vision. Vol. 9. 2017. Link
[2] Fast Image Processing Code Link
[3] MIT-Adobe FiveK Dataset Link
[4] Xu, Li, et al. “Image smoothing via L 0 gradient minimization.” ACM Transactions on Graphics (TOG). Vol. 30. No. 6. ACM, 2011. Link
[5] Nguyen, Rang MH, and Michael S. Brown. “Fast and effective L0 gradient minimization by region fusion.” Proceedings of the IEEE International Conference on Computer Vision. 2015. Link
[6] Johnson, Justin, Alexandre Alahi, and Li Fei-Fei. “Perceptual losses for real-time style transfer and super-resolution.” European Conference on Computer Vision. Springer, Cham, 2016.
[7] Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017). Image-to-image translation with conditional adversarial networks. arXiv preprint.
[8] Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. “Image style transfer using convolutional neural networks.” Computer Vision and Pattern Recognition (CVPR), 2016 IEEE Conference on. IEEE, 2016.
Contributions
Phillip Kuznetsov:
- Trained and debugged style transfer loss model
- Ran style transfer baselines
- Built webapp
Gabriel Gardner:
- Built basic PyOpenGL renderer
- ran and debugged L2 loss model
Stefan Palombo:
- Built plane data sets using PyOpenGL
- Trained and debugged Pix2Pix model
Appendix
Fully Convolutional Network Architecture
